Разбор
поиск в ширину (или BFS) — это модификация классического алгоритма поиска в ширину (BFS), который используется для нахождения кратчайших путей в графах. Отличие этого алгоритма в том, что веса рёбер в графе могут принимать только значения или , что позволяет значительно оптимизировать поиск.
Постановка задачи. Представим, что у нас есть взвешенный граф, в котором веса рёбер — это либо , либо . Например, такой граф можно встретить, когда мы работаем с городом, в котором некоторые дороги бесплатные (вес ), а по другим приходится платить (вес ). Мы хотим найти кратчайший путь от одной вершины графа до другой с учётом этих весов.
Проблема стандартного алгоритма поиска в ширину. Классический алгоритм поиска в ширину (BFS) имеет оценку сложности и используется для поиска кратчайших путей в графе, но он подходит только для графов, где все рёбра имеют одинаковый вес. В случае, если веса рёбер различны, такой подход уже неэффективен — для этих целей обычно применяют алгоритм Дейкстры с оценкой сложности или . Но для графов с весами только и существует более быстрый подход — BFS.
0-1 BFS Алгоритм
В BFS мы используем двустороннюю очередь (deque). Идея состоит в следующем:
Мы начинаем с исходной вершины и добавляем её в очередь с начальным расстоянием, равным .
При обработке каждой вершины (которая извлекается из головы очереди) рассматриваем её соседей :
Если у ребра вес , то соседняя вершина помещается в начало очереди с текущим расстоянием .
Если у ребра вес , то соседняя вершина помещается в конец очереди с увеличением расстояния на единицу .
Это позволяет эффективно поддерживать правильный порядок обработки вершин: вершины, достижимые через рёбра с меньшим весом, обрабатываются раньше.
Таким образом, использование двусторонней очереди гарантирует, что мы всегда имеем доступ к вершине с минимальным расстоянием в начале очереди, а сложность работы алгоритма остаётся .
Релаксация рёбер при поиске в ширину похожа на классическую релаксацию в алгоритме Дейкстры, но отличается использованием двусторонней очереди (deque) вместо очереди с приоритетами (priority queue) для упорядочивания вершин на основе веса рёбер.
Рассмотрим следующий пример. Инициализируем массив кратчайших расстояний и очередь :
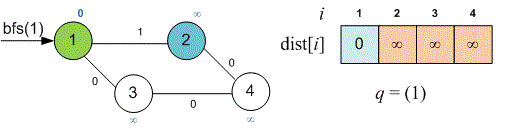
Рассмотрим ребра, исходящие из вершины . Релаксируем ребра и . Вершина будет занесена в начало очереди, а вершина в конец очереди.
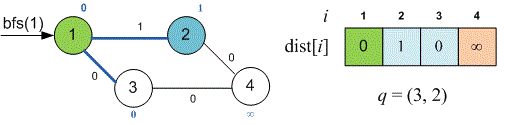
Однако значение не является окончательным. Пройдем по ребру и установим , . Затем рассмотрим ребро и значение установится равным . Таким образом, принимало два различных значения в результате релаксации (сначала , потом ).
Пример
Граф, приведенный в примере, имеет вид:
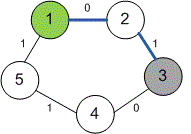
Длина кратчайшего пути из вершины в равна , а сам кратчайший путь имеет вид: .
Реализация алгоритма
Объявим константу бесконечность.
#define INF 0x3F3F3F3F
Объявим массив кратчайших расстояний и список смежности графа .
vector<int> dist; vector<vector<pair<int, int>>> g;
Функция bfs реализует поиск в ширину из вершины .
void bfs(int start)
{Инициализируем массив кратчайших расстояний .
dist = vector<int>(n + 1, INF); dist[start] = 0;
Объявим очередь и занесем в нее стартовую вершину .
deque<int> q; q.push_back(start);
Продолжаем алгоритм поиска в ширину пока очередь не пустая.
while (!q.empty())
{Извлекаем из головы очереди вершину .
int v = q.front(); q.pop_front();
Перебираем ребра, исходящие из вершины .
for (auto edge : g[v])
{
int to = edge.first;
int w = edge.second;Текущее ребро имеет вес . Проводим его релаксацию.
if (dist[to] > dist[v] + w)
{Если ребро релаксирует, то пересчитываем кратчайшее расстояние .
dist[to] = dist[v] + w;
В зависимости от веса ребра добавляем вершину в конец или в начало очереди.
if (w == 1)
q.push_back(to);
else
q.push_front(to);
}
}
}
}Основная часть программы. Читаем входные данные.
scanf("%d %d %d %d", &n, &m, &s, &d);
g.resize(n + 1);Читаем граф.
for (i = 0; i < m; i++)
{
scanf("%d %d %d", &a, &b, &w);
g[a].push_back({ b, w });
g[b].push_back({ a, w });
}Запускаем поиск в ширину со стартовой вершины .
bfs(s);
Выводим кратчайшее расстояние до вершины .
printf("%d\n", dist[d]);