Вне контекста
Наступило время года, когда проходят выборы. Политические речи звучат повсюду, и ваш друг, диванный аналитик, обожает находить цитаты политиков и использовать их вне контекста. Вы хотите помочь своему другу, разработав метод поиска в тексте для заданных шаблонов.
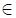
Один из самых мощных способов выразить шаблон поиска текста — это использование контекстно-свободной грамматики (CFG). CFG используется для генерации строк и определяется как 4-кортеж (V, Σ, R, S), где V — это множество переменных, Σ — это множество терминальных символов, S V — начальная переменная, а R — это множество правил. Каждое правило в R имеет вид

что означает, что голова правила (переменная слева от стрелки) может быть заменена на продукцию правила, последовательность переменных и терминальных символов справа от стрелки, всякий раз, когда она появляется. Возможно, что правая часть правила будет пустой, что указывает на то, что переменная слева может быть заменена на пустую строку.
Грамматика генерирует строку терминалов через процесс вывода. Вывод начинается с последовательности, которая изначально состоит только из начальной переменной. Затем, пока все переменные не будут удалены, мы многократно заменяем любую переменную в текущей последовательности на любую из продукций этой переменной.
В качестве примера, вот правила для грамматики с начальной переменной A (слева) и пример вывода (справа).

Напишите программу, которая может искать в тексте подстроки, которые могли быть сгенерированы данной CFG.
Входные данные
Для этой задачи V — это множество заглавных букв английского алфавита, а Σ — это множество строчных букв английского алфавита. Ввод начинается с описания R, правил CFG. Первая строка содержит целое число 1 ≤ n ≤ 30, указывающее количество следующих правил. Следующие n строк описывают одно правило в формате

То есть заглавная буква, один пробел, стрелка, один пробел и строка из нуля или более заглавных или строчных букв. Продукции правил имеют длину не более 10 символов. Начальная переменная S — это голова первого данного правила.
После правил следуют не более 100 строк текста для поиска, каждая длиной не более 50 символов. Каждая строка ввода состоит только из строчных английских букв и пробелов. Ввод заканчивается в конце файла.
Выходные данные
Для каждой строки поиска напечатайте строку, содержащую самую длинную непустую подстроку, которую грамматика может сгенерировать. Если есть несколько подстрок одинаковой длины, укажите ту, которая появляется раньше в строке. Если подходящей подстроки нет, напечатайте NONE заглавными буквами.